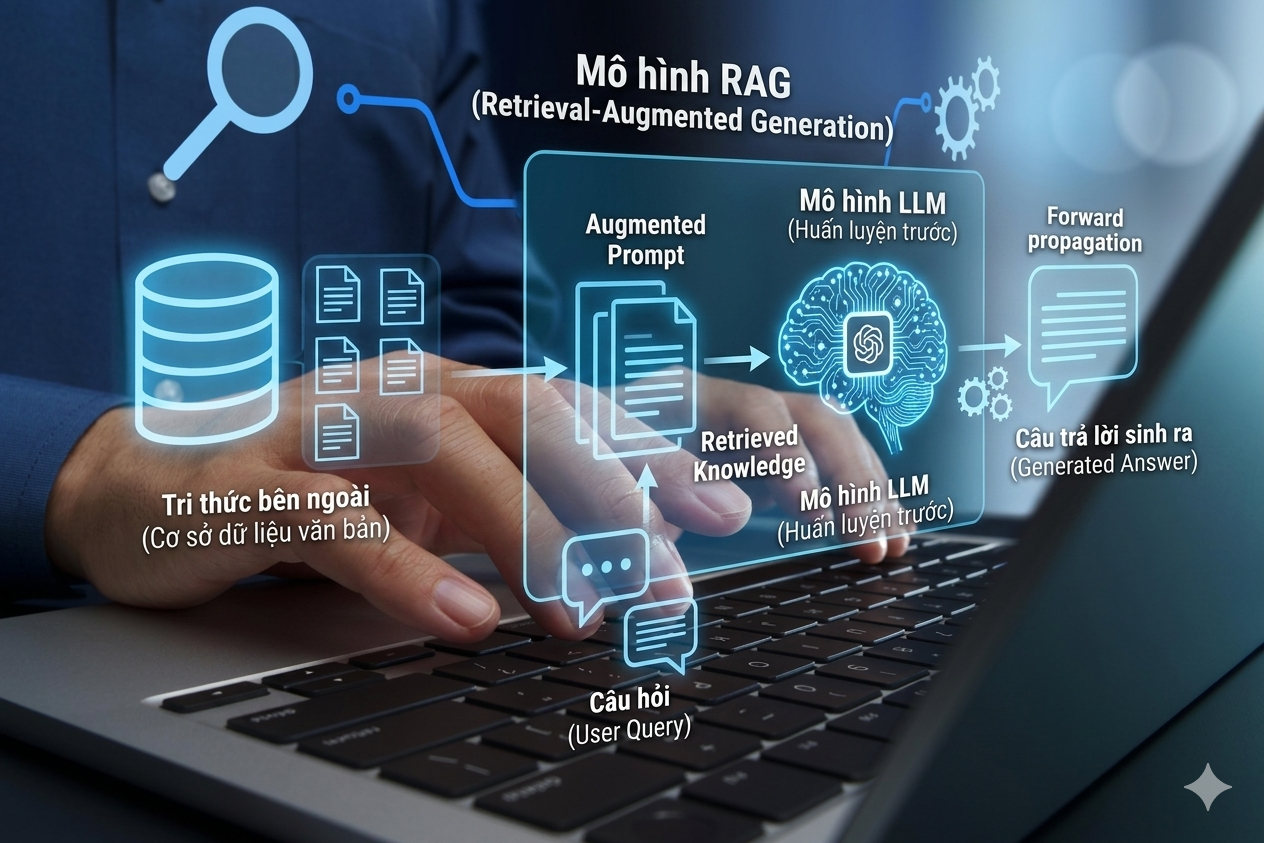

Các mô hình ngôn ngữ lớn (LLM) vẫn gặp hạn chế về dữ liệu lỗi thời và hiện tượng “ảo giác” thông tin. Mô hình RAG (Retrieval-Augmented Generation) ra đời như giải pháp giúp AI truy xuất dữ liệu thực tế để nâng cao độ chính xác. Trong bài viết này, Lilytech sẽ cùng bạn tìm hiểu RAG là gì và cách công nghệ này hoạt động trong thực tế.
Mô Hình RAG Là Gì?
MMô hình RAG (Retrieval-Augmented Generation) là một kiến trúc lai kết hợp hai khả năng mạnh mẽ: truy xuất thông tin (Retrieval) và tạo sinh nội dung (Generation). Thay vì chỉ dựa vào kiến thức đã được “nhồi” cố định trong hàng tỷ tham số của mô hình ngôn ngữ lớn (LLM), RAG cho phép mô hình chủ động tìm kiếm thông tin liên quan từ một cơ sở dữ liệu bên ngoài trước khi đưa ra câu trả lời.
Ý tưởng cốt lõi của mô hình RAG là gì nằm ở việc bổ sung ngữ cảnh (context) chất lượng cao vào prompt của LLM. Nhờ đó, AI không còn phải “tưởng tượng” mà có thể dựa trên tài liệu thực tế, đáng tin cậy để sinh ra câu trả lời.
Mọi người cũng xem:
Lịch Sử Ra Đời Và Sự Phát Triển Của RAG
Ý tưởng RAG được Lewis et al. giới thiệu lần đầu tiên vào năm 2020 trong bài báo “Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks”. Từ đó đến nay, công nghệ đã phát triển qua nhiều phiên bản: Naive RAG, Advanced RAG và Modular RAG. Mỗi thế hệ đều khắc phục những hạn chế của thế hệ trước, đặc biệt về độ chính xác truy xuất và chất lượng ngữ cảnh được đưa vào.
Kiến Trúc RAG Chi Tiết
Hệ thống RAG gồm bốn thành phần chính phối hợp chặt chẽ để tạo ra câu trả lời chính xác và có ngữ cảnh
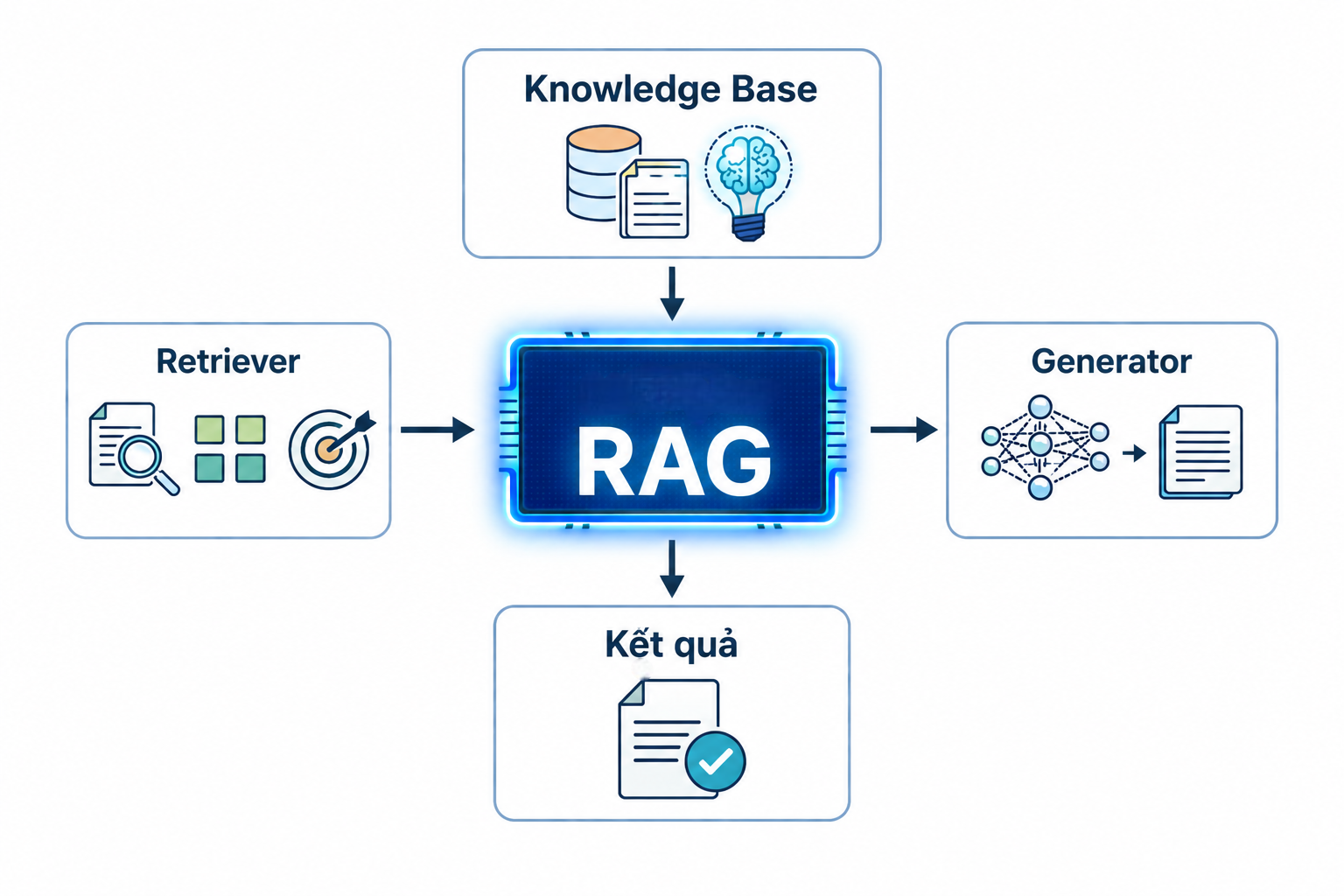
Retrieval System (Retriever): Chịu trách nhiệm tìm kiếm tài liệu liên quan. Sử dụng mô hình embedding (như text-embedding-ada-002, BGE, Voyage…) để chuyển văn bản thành vector và truy tìm theo độ tương đồng cosine. Đây cũng là nơi nhiều thuật toán Machine Learning được ứng dụng để cải thiện khả năng truy xuất.
Knowledge Base (Vector Database):Lưu trữ dữ liệu dưới dạng vector. Các công cụ phổ biến: Pinecone, Weaviate, Qdrant, Chroma, Milvus.
Generator (LLM): Mô hình ngôn ngữ lớn (LLM) nhận prompt đã được bổ sung ngữ cảnh để sinh ra câu trả lời cuối cùng.
Kết quả : Hệ thống trả về phản hồi đã được xử lý, đảm bảo tính chính xác và giảm hiện tượng hallucination.
Các Loại RAG Phổ Biến Hiện Nay
Tùy theo cách tổ chức quy trình, người ta chia RAG thành:
- Naive RAG: Truy xuất → Bổ sung → Sinh (cách tiếp cận cơ bản nhất).
- Advanced RAG: Tối ưu hóa truy xuất bằng query rewriting, metadata filtering, reranking.
- Modular RAG: Kiến trúc linh hoạt với nhiều module có thể thay thế hoặc kết hợp (Route, Predict, Fusion…).
Cơ Chế Hoạt Động Của Mô Hình RAG Theo Từng Bước
Cơ chế hoạt động của mô hình RAG có thể được chia thành 6 giai đoạn chính, hoạt động theo thời gian thực khi người dùng đưa ra câu hỏi:
| Giai đoạn | ⚙️ Tên bước | 🧠 Mô tả chi tiết |
|---|---|---|
| 1 | Xử lý câu hỏi đầu vào | Chuyển đổi query của người dùng thành vector embedding bằng mô hình embedding. Một số hệ thống còn thực hiện query rewriting hoặc query expansion để cải thiện chất lượng truy xuất. |
| 2 | Truy xuất thông tin (Retrieval) | So sánh vector query với hàng triệu vector trong cơ sở dữ liệu để lấy ra Top-K chunk (thường 3–10) có độ tương đồng cao nhất. Đây là bước then chốt quyết định chất lượng thông tin. |
| 3 | Tái xếp hạng (Reranking) | Các tài liệu được lấy ra ban đầu sẽ được mô hình Cross-Encoder đánh giá lại để chọn ra những đoạn thực sự liên quan nhất, giúp giảm nhiễu thông tin. |
| 4 | Tạo prompt bổ sung (Augmentation) | Ghép các đoạn văn bản được chọn vào prompt có cấu trúc rõ ràng, ví dụ: “Dựa trên thông tin dưới đây, hãy trả lời câu hỏi một cách chính xác và chi tiết: [Context] Câu hỏi: [Question]”. |
| 5 | Sinh câu trả lời (Generation) | Mô hình LLM (GPT‑4o, Claude 3.5, Gemini 1.5, Llama 3…) sử dụng toàn bộ ngữ cảnh để tạo câu trả lời chính xác hơn, giảm mạnh hiện tượng hallucination. |
| 6 | Hậu xử lý và trả kết quả (Post‑Processing) | Kiểm tra tính nhất quán, trích dẫn nguồn hoặc tóm tắt lại câu trả lời trước khi gửi cho người dùng. |
Lợi Ích Nổi Bật Khi Áp Dụng Cơ Chế Hoạt Động Của RAG
Việc hiểu rõ cách hoạt động của RAG giúp chúng ta thấy rõ giá trị thực sự mà kiến trúc này mang lại
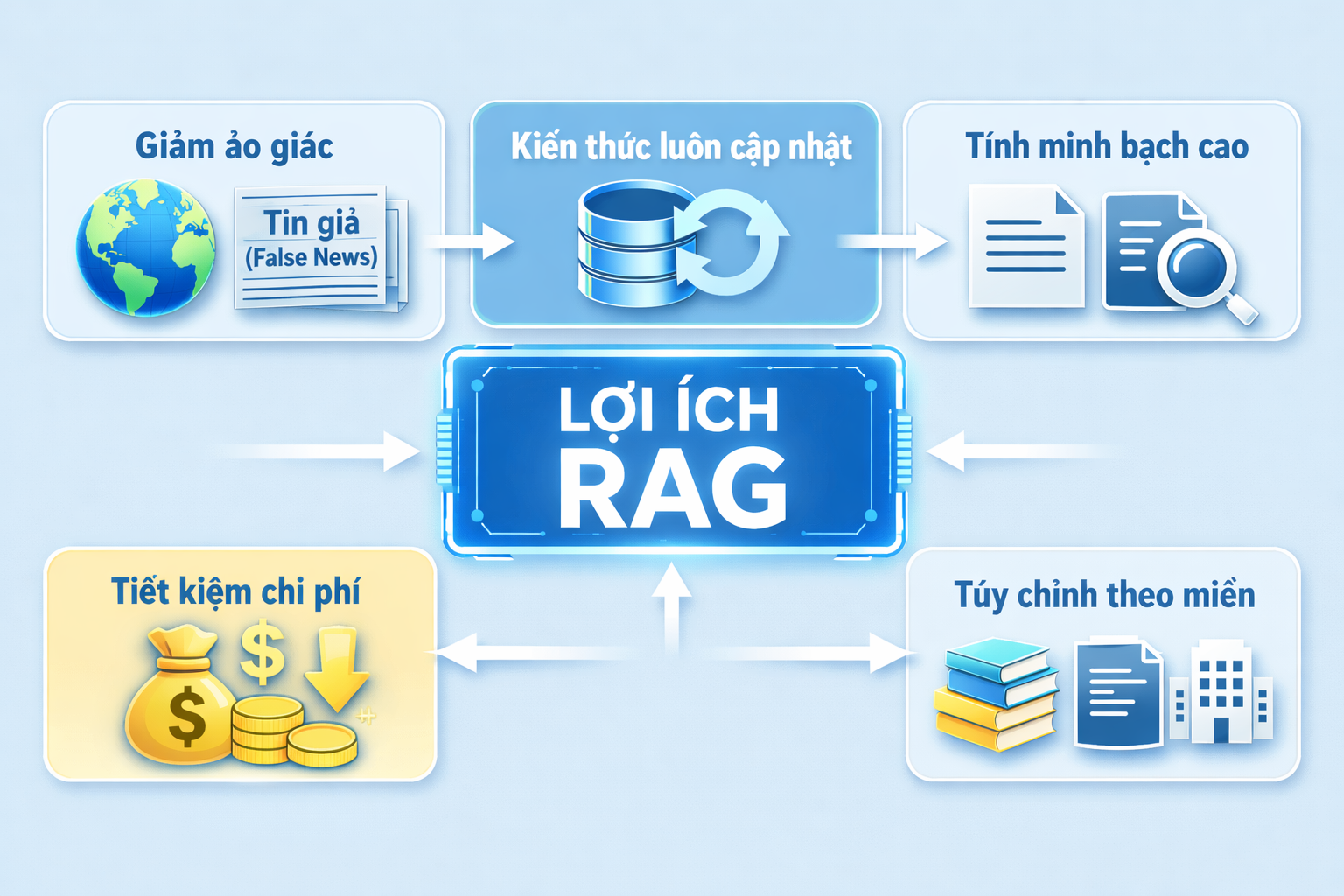
- Giảm thiểu hallucination: AI có tài liệu cụ thể để dựa vào thay vì “bịa” thông tin.
- Kiến thức luôn được cập nhật: Chỉ cần cập nhật vector database là hệ thống có ngay thông tin mới nhất mà không cần retrain mô hình.
- Tính minh bạch cao: Có thể trích dẫn nguồn tài liệu cụ thể mà AI đang dựa vào.
- Tiết kiệm chi phí: Rẻ hơn rất nhiều so với việc fine-tuning hoặc tiếp tục huấn luyện LLM.
- Tùy chỉnh theo domain: Tùy chỉnh theo domain: Dễ dàng đưa kiến thức chuyên môn của doanh nghiệp (hợp đồng, chính sách, tài liệu kỹ thuật…) vào AI, tạo nền tảng cho việc xây dựng enterprise AI agents phục vụ vận hành nội bộ.
Thách Thức Và Xu Hướng Phát Triển Của RAG
Mặc dù mạnh mẽ, cơ chế hoạt động của mô hình RAG vẫn tồn tại một số thách thức
- Vấn đề “Lost in the Middle” khi ngữ cảnh quá dài.
- Chi phí tính toán và độ trễ khi truy xuất trên tập dữ liệu cực lớn.
- Chất lượng embedding quyết định trực tiếp hiệu suất tổng thể.
- An ninh dữ liệu và quyền riêng tư khi đưa tài liệu nội bộ vào vector store.
Hiện nay, cộng đồng đang hướng tới các giải pháp Graph RAG, Agentic RAG, CRAG (Corrective RAG) và Self-Adaptive RAG nhằm nâng cao khả năng tự điều chỉnh và suy luận của hệ thống. Những kiến trúc này đang mở rộng mạnh mẽ sang chatbot doanh nghiệp và tự động hóa dịch vụ quy mô lớn.
Kết Luận
Cơ Chế Hoạt Động Của Mô Hình RAG: Bí Mật Giúp AI Trả Lời Chính Xác Hơn nằm ở khả năng kết nối thông minh giữa truy xuất kiến thức thời gian thực và sức mạnh tạo sinh của LLM. Việc nắm vững kiến trúc RAG và cách hoạt động của RAG không chỉ giúp bạn hiểu sâu hơn về công nghệ mà còn mở ra rất nhiều cơ hội ứng dụng thực tế cho doanh nghiệp.
Nếu bạn đang xây dựng chatbot hỗ trợ khách hàng, hệ thống hỏi đáp nội bộ hoặc công cụ tra cứu tài liệu thông minh, RAG chính là lựa chọn tối ưu nhất hiện nay. Hãy bắt đầu với một knowledge base chất lượng cao, hệ thống embedding phù hợp và liên tục tối ưu quy trình retrieval – đây chính là chìa khóa để sở hữu một hệ thống AI đáng tin cậy và chính xác.
Bạn đang áp dụng RAG trong dự án nào? Hãy để lại bình luận bên dưới để cùng thảo luận sâu hơn về tối ưu hóa cơ chế hoạt động của mô hình RAG.



