

Inference là giai đoạn mà mô hình AI sử dụng những gì đã học được để đưa ra dự đoán, phân loại hoặc ra quyết định trên dữ liệu mới. Đây là bước quan trọng giúp trí tuệ nhân tạo hoạt động trong thực tế, từ chatbot, nhận diện hình ảnh đến các hệ thống gợi ý thông minh. Trong bài viết này, Lilytech sẽ giúp bạn hiểu rõ Inference trong AI là gì và cách quá trình này vận hành.
Inference Trong AI Là Gì?
Inference trong AI là quá trình mà một mô hình trí tuệ nhân tạo đã được huấn luyện (trained model) sử dụng để suy luận và đưa ra kết quả dự đoán trên dữ liệu mới mà nó chưa từng thấy trong quá trình huấn luyện. Đây là giai đoạn “triển khai” thực sự của AI, nơi mô hình chuyển từ việc học sang việc áp dụng kiến thức.

Khác với giai đoạn training đòi hỏi hàng nghìn GPU và thời gian dài, inference thường được tối ưu để chạy trên thiết bị edge, mobile, hoặc server thông thường với yêu cầu về tốc độ cao và độ trễ thấp.
Mọi người cũng xem:
Inference Deep Learning Trong Học Sâu
Inference deep learning đặc biệt quan trọng với các mạng nơ-ron sâu (Deep Neural Networks). Khi một mô hình CNN, Transformer hay mô hình ngôn ngữ lớn LLM hoàn tất huấn luyện, trọng số (weights) và bias được cố định. Trong giai đoạn inference, dữ liệu đầu vào sẽ được đưa qua các tầng mạng theo chiều xuôi (forward pass) để tính toán xác suất đầu ra.
Ví dụ: Một mô hình nhận diện khuôn mặt sau khi huấn luyện sẽ sử dụng inference để dự đoán “đây là ai” chỉ trong vài mili-giây khi nhận được hình ảnh từ camera.
Quá Trình Inference Trong AI Hoạt Động Như Thế Nào?
Quá trình inference trong AI bao gồm nhiều bước được tối ưu nghiêm ngặt để đảm bảo tốc độ và độ chính xác. Hiểu rõ cơ chế này giúp kỹ sư xây dựng hệ thống AI hiệu suất cao.
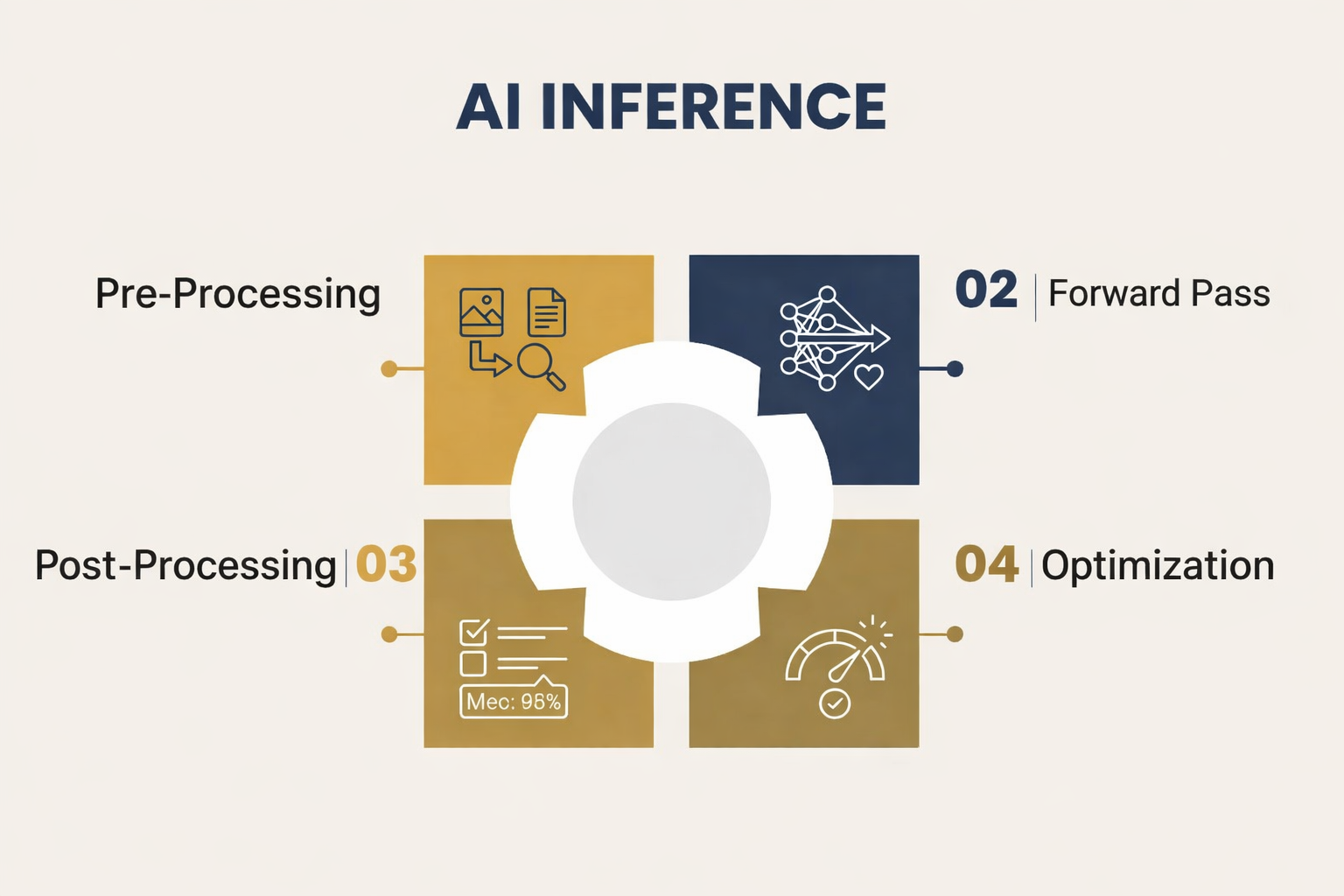
Các Bước Chính Trong AI Model Inference
- Chuẩn bị dữ liệu đầu vào (Pre-processing): Resize ảnh, chuẩn hóa giá trị pixel, chuyển văn bản thành token, hoặc trích xuất đặc trưng.
- Forward Pass: Dữ liệu được truyền qua toàn bộ các tầng của mô hình đã huấn luyện để tính toán kết quả.
- Post-processing: Chuyển đổi đầu ra thô thành kết quả có ý nghĩa (ví dụ: chuyển logit thành nhãn lớp, áp dụng Non-Maximum Suppression trong object detection).
- Tối ưu hóa bộ nhớ và tính toán: Sử dụng kỹ thuật quantization, pruning, distillation để giảm độ trễ.
Vai Trò Của Forward Propagation Trong Inference
Trong AI model inference, forward propagation là trái tim của quá trình. Mô hình sử dụng chính xác các trọng số đã học trong giai đoạn training nhưng không cập nhật chúng nữa. Mọi phép tính gradient đều bị tắt, giúp tiết kiệm đáng kể tài nguyên tính toán và bộ nhớ.
Inference Và Training Khác Nhau Gì?
Rất nhiều người mới bắt đầu nhầm lẫn giữa hai giai đoạn này. Dưới đây là bảng so sánh chi tiết giữa inference và training:
Đặc điểm Training Inference Mục tiêu Học hỏi từ dữ liệu để tìm ra các trọng số (weights) tối ưu. Sử dụng các trọng số đã học để dự đoán kết quả cho dữ liệu mới. Cơ chế tính toán Bao gồm Forward pass và Backward pass (cập nhật trọng số). Chỉ thực hiện Forward pass (không cập nhật trọng số). Dữ liệu Sử dụng tập dữ liệu lớn đã được gán nhãn sẵn. Sử dụng dữ liệu thực tế (thường là dữ liệu mới, chưa có nhãn). Yêu cầu tài nguyên Rất cao (cần nhiều GPU/TPU, thời gian dài). Ưu tiên tốc độ, có thể chạy trên CPU, thiết bị di động hoặc Edge devices. Đo lường hiệu quả Tối ưu hóa hàm mất mát (Loss function). Tập trung vào độ trễ (Latency), thông lượng (Throughput) và độ chính xác thực tế.
Sự khác biệt này giải thích tại sao nhiều công ty đầu tư mạnh vào giai đoạn tối ưu inference sau khi đã có mô hình training tốt.
Ứng Dụng Thực Tế Của AI Model Inference
Inference trong AI đang hiện diện khắp nơi trong cuộc sống hàng ngày

- Nhận diện hình ảnh và video: Camera an ninh, xe tự lái, lọc ảnh trên điện thoại.
- Xử lý ngôn ngữ tự nhiên: Chatbot, trợ lý ảo AI, dịch máy thời gian thực, tóm tắt văn bản.
- Khuyến nghị: Netflix, Shopee, TikTok sử dụng inference để gợi ý nội dung tức thì.
- Y tế: Chẩn đoán bệnh từ ảnh X-quang, MRI chỉ trong vài giây.
- Sản xuất: Kiểm tra lỗi sản phẩm trên dây chuyền tự động.
Mỗi ứng dụng đều đòi hỏi inference phải nhanh, ổn định và tiết kiệm năng lượng, đặc biệt khi triển khai trên thiết bị biên (edge AI).
Cách Tối Ưu Hóa Inference Deep Learning
Để đưa inference deep learning vào sản xuất thực tế, các kỹ sư thường áp dụng các kỹ thuật sau:
- Quantization: Giảm độ chính xác của trọng số từ 32-bit xuống 8-bit hoặc thấp hơn.
- Pruning: Loại bỏ các kết nối ít quan trọng trong mạng nơ-ron.
- Knowledge Distillation: Huấn luyện một mô hình nhỏ (student) học lại từ mô hình lớn (teacher).
- Model Compression & Acceleration: Sử dụng TensorRT, ONNX Runtime, OpenVINO để tăng tốc inference.
- Batch Inference: Xử lý nhiều yêu cầu cùng lúc để tăng throughput.
Việc tối ưu hóa có thể giúp giảm thời gian phản hồi từ 500ms xuống dưới 50ms và giảm tiêu thụ năng lượng đáng kể.
Kết Luận
Cách Trí Tuệ Nhân Tạo Đưa Ra Dự Đoán chính là chìa khóa để biến các mô hình AI trên giấy tờ thành những ứng dụng thực tế có giá trị. Hiểu rõ bản chất của AI inference, sự khác biệt giữa inference và training, cùng các kỹ thuật tối ưu sẽ giúp bạn triển khai giải pháp AI hiệu quả hơn, tiết kiệm chi phí và mang lại trải nghiệm tốt nhất cho người dùng cuối.
Trong tương lai, khi AI tiếp tục được triển khai rộng rãi trên edge devices, khả năng tối ưu inference sẽ trở thành lợi thế cạnh tranh quan trọng. Nếu bạn đang xây dựng hoặc triển khai hệ thống AI, hãy bắt đầu bằng việc đánh giá hiệu suất inference của mô hình hiện tại và áp dụng các kỹ thuật tối ưu phù hợp. Đây chính là bước đi then chốt để AI không chỉ “thông minh” mà còn “thực tế” và “kinh tế”.



